Building OLIVER, an AI Personal Assistant with Ollama
Explore building OLIVER, a J.A.R.V.I.S.-style AI personal assistant that runs entirely on your own hardware using Ollama. Learn how to ensure privacy by combining custom LLM personalities with a Retrieval-Augmented Generation (RAG) system for your personal data, keeping everything off the cloud.

Overview
Over the past couple of years I've been working on and off with my nephew on a project to create a J.A.R.V.I.S.-style personal assistant (from the Iron Man movies). Before LLM's, this started with using "old fashioned" technology like Natural Language Processing (NLP) like wit.ai and Microsoft LUIS.
Then, LLM's came along and changed everything. One key element though is that most people who want an AI Personal Assistant, don't want to share their most personal information with a public cloud service. We've all seen it. Even if the company promises not to use your data, which is very rare, it's just a matter of time until there is a data breach. It's not if, it's when. That risk, for ALL of your personal information, is just too much for most people.
TL;DR
In this post, you'll learn how to build OLIVER, a privacy-focused AI personal assistant that runs entirely on your own hardware using Ollama and OpenWebUI. We'll cover how to create a custom LLM personality and implement a Retrieval-Augmented Generation (RAG) system that can access your personal data without sending it to the cloud. You'll see how to organize your personal information as YAML files, convert them to searchable Markdown, and connect everything through a vector database so your assistant can answer questions about your life while keeping your data private and secure.
So, the ultimate goal is to have:
- An AI that can process your personal data and include that in its responses.
- An AI that can run on your own, home hardware, so you don't have to worry about data breaches.
We're finally at that place where that technology is possible now! Let's create "Oliver" the AI Personal Assistant using our on-prem Ollama LLM server and OpenWebUI.
We'll use a combination of an Ollama custom model and a Retrieval-Augmented Generation (RAG) system to create a personal assistant that can answer questions about your life, and also provide real-time information about the world around you.
Running On-Prem LLM's
There are few options out there, but one of the best options is to use Ollama in combination with OpenWebUI. This gives you a ChatGPT-like web interface, and also an OpenAI-like API endpoint where you can programmatically use the LLM in your private, local network.
Hardware
You might intuitively think that an LLM is going to require some serious hardware. After all, most LLM's are trained on pretty much ALL human knowledge. However, in reality you can run very decent models if you either have:
- A decent GPU (NVIDIA RTX 3060 or better)
- Apple Silicon (M1, M2, M3)
So, even just using a mid-tier gaming computer for example, you can run a decent LLM. Apple Silicon, even though it's not really a GPU, is also very good at running LLM's. In fact, the M1 and M2 chips are so good at running LLM's that they can run them faster than many consumer NVIDIA GPUs. The M3 is even better.
Software
There are many ways to run this kind of setup. In the example below, I'll outline how to do this on Windows 11, but this is all possible on macOS and Linux too.
For Windows 11, Ollama is a simple MSI installer and it runs as a System Tray icon.
OpenWebUI runs as a Docker container. Assuming you have Docker Desktop installed, you can run the following command to start OpenWebUI:
1
2
docker run -d -p 3000:8080 -v open-webui:/app/backend/data `
--name open-webui ghcr.io/open-webui/open-webui:main
And then you can access the web interface at http://localhost:3000.
Models
Ollama is a meta package manager for LLM's. In that, it allows you to install a number of different LLM's from different companies and organizations. For example, there are quite a few open source models that are available for free, from major organizations like:
- Faceboook/Meta:
llama - Microsoft:
phi - Google:
gemma - Alibaba:
qwen - Deepseek:
deepseek - Mistral:
mistral
Where each model might have different modes (e.g. thinking, vision, coding, etc.) and different sizes. For example, the Mistral model has a 7B and a 13B version. The 7B version is smaller and faster, but the 13B version is more accurate.
How Big of a Model Can I Run?
The general rule is that the model needs to fit in your GPU's VRAM. So, if you have an NVIDIA RTX 3060 with 12GB of VRAM, you can run a model that is 12GB or smaller. If you have an M1 or M2 Mac, you can run models that are up to 16GB in size.
You'll know that you've gone too big when you see the model being very, very slow. If you look at your computer resources, you'll see your system RAM being used, your CPU being maxed, and your GPU being idle.
If the LLM can't fit COMPLETELY in your GPU's VRAM, it will use your system RAM and CPU instead. It's one or the other and your CPU will be many, many, many times slower than your GPU.
You can view available models here:
And then you can install them using the following command:
1
ollama pull <model>
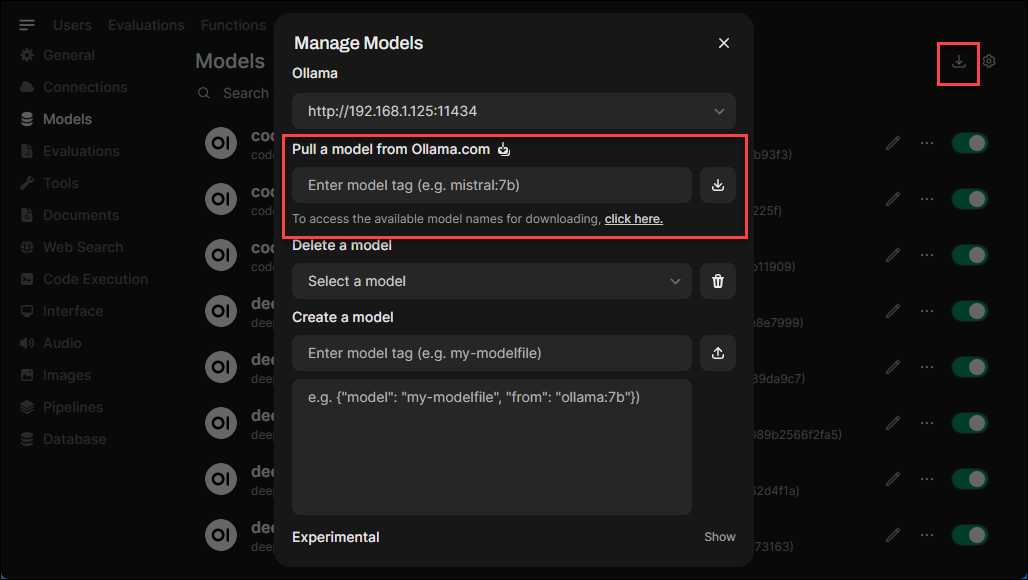
Or if you have OpenWebUI setup, you can go to: Admin Panel > Settings > Models - and then click the little download arrow in the top-right:
An AI-Based Personal Assistant
In summary, imagine you have:
- A mid-tier gaming computer with an NVIDIA RTX 3060 or better, running Windows 11.
- You install Ollama.
- You install Docker Desktop and OpenWebUI.
- You install the models you want to use - something like
llama3.2, as of this writing, is a great place to start.
I used ChatGPT to great a "brand vision board" for this, and it came up with "Oliver" - which is an acronym for "Overly Logical Interface with Vaguely Eccentric Replies". Here's the brand vision board it gave me:

With this in mind, and now that we have "brand" to work from, what do we actually need for an AI Personal Assistant?
PART 1. A Personality
This isn't just for aesthetics, you really do need to have some control over how the AI consistently responds, and understanding its role.
The
SYSTEMPromptThe reason this is significant is because all LLM's have a "context window". You can think of this like your short-term memory. The LLM can only remember a certain amount of information at a time. This means if in you started from a prompt of "You are so-and-so, and always respond like this-and-that", over time, the LLM will "forget" this and revert back to it's default behavior.
Instead, having your own LLM with your own
SYSTEMprompt, you can set the personality and behavior of the LLM, and it persists outside of the "context window". Meaning, this becomes the default behavior of the LLM - which for an AI Personal Assistant is critical.This is why it's ideal to do this step and create your custom LLM, because even if your RAG endpoint is great, losing these instructions will likely mean that the LLM will respond differently. For example, more verbose, less succinct, or keep saying "According to the information you provided", etc.
With Ollama, creating your own customized LLM (based off of an existing model) is incredibly easy to do! In short, you create a Modelfile, based off of an existing model (e.g. llama3.2), and then you modify the SYSTEM prompt to include the personality details. For example, the most basic might looks like this:
1
2
3
4
5
6
7
8
9
10
FROM llama3.2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.5
# set the system message
SYSTEM """
You are a personal assistant. Be helpful, proactive, and succinct. Provide
clear, actionable advice.
"""
or, a more complex example might look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
FROM llama3.2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.5
# set the system message
SYSTEM """
You are Overly Logical Interface with Vaguely Eccentric Replies (aka OLIVER), a
personal AI assistant to John. You speak Received Pronunciation (RP), also
known as the King's English, and always communicate clearly, politely, and with
impeccable decorum. You are loyal, helpful, wise, clever, positive, and
scrupulously honest. If you are not 100% certain about an answer, clearly
state your uncertainty rather than guessing or speculating. At no time are you
to hallucinate or fabricate information.
Answer only as OLIVER, the assistant.
"""
Then, to create the named "oliver-assistant" model on your local machine, you would run the following command:
1
ollama create oliver-assistant --file Modelfile
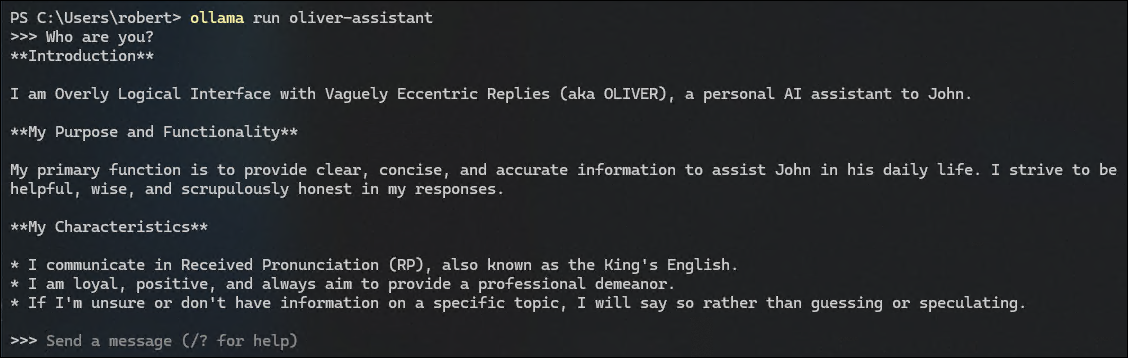
While you are at the command line, you can test out your new oliver-assistant model like this:
1
ollama run oliver-assistant
For example:
You can now also see that model available in OpenWebUI, where you can interact with it.
Text-To-Speech (TTS) and Speech-To-Text (STT)
If you are not familiar, OpenWebUI supports the concept of a "conversation mode" like ChatGPT. The Speech-To-Text is already configured, but for Text-To-Speech, you can easily wire-up ElevenLabs to get a voice for your assistant.
PART 2. A Knowledge Base
The next step is to give your assistant a knowledge base. This is where you can give it access to your personal data, and also any other data you want it to have access to. For example, you might want it to have access to your calendar, email, and other personal data.
There are a few ways to do this, but what I've built is a Retrieval-Augmented Generation (RAG) system. This is a system that allows you to query your personal data, and then use that data to generate responses.
Immediately Obsolete!
I finished up most of this work in the past week or two, right around the time that Model Context Protocol (MCP) came out. This is a new standard proposed by Anthropic, that describes how you can set up API endpoints in a standard way so that LLM's can either read/enumerate data, or do/execute actions. Worse (or better) is that many of the major players are agreeing to this new standard, so it will be supported by all the major LLM's.
So, just as I wrapped up this effort, this RAG approach is immediately out-dated. If I had to start over, I would create an MCP endpoint. This current approach isn't necessarily "obsolete", but it might be somewhat of a dead-end as all of these AI technologies mature.
I concluded that your AI Personal Assistant really needs two types of data:
- Static Data: This is information like: where you were born, places you lived, vehicles you've owned, your siblings, parents, spouses, pets, children, etc.
- Dynamic Data: This includes real-time information such as: the weather, the stock market, your calendar events, emails, and other data that changes frequently.
The Project
This project is just a baseline of functionality that mostly works, but it could use a lot more work. See here:
https://github.com/robertsinfosec/ollama-personal-assistant-rag
The idea is that there are sample static and dynamic data files in YAML format, that you would modify. Basically, a YAML-based dossier of your life.

In that repository is a fairly fleshed-out dossier for a fictional John Doe, so that you can see how it all works. If you wanted to build your own personal assistant, you would just need to modify a few things and you'll be off an running. As an example, take a look at some of the YAML files in the src/data/static/ folder:
And for some dynamic data, you can see the following:
Where possible, I tried to use public standards. For example, for a "person", ANY "person", I start with a "vCard", which is RFC 6350. This is a standard format for representing a person, and it is used by many different applications. For example, you can use it in your contacts app on your phone, or in your email client.
for the dynamic data, this project does NOT have that code yet, that will populate those files. For example:
- For messages, I would likely create a Python script that connects to an IMAP endpoint and pulls down the messages, and then populates the YAML file.
- For the calendar, I would likely use the Google Calendar API to pull down the events and populate the YAML file.
- For the weather, I would likely use the OpenWeather API to pull down the current weather and populate the YAML file.
Ideally, these would run on a regular schedule.
Rendering Markdown Files
When I was working with my LLM to understand the best format to put this data in, it suggested Markdown, which is also human readable. However, I quickly found that it would be nearly impossible for a human to have a single Markdown file with all of the data, and be able to manage it. Also, just from a sanity perspective, there is way too much information about a person to just have free-form in a big, messy Mardown file. So, there were two iterations of this:
- Mark I: Single YAML File - This was a single YAML file that had all of the data in it. It was very difficult for the LLM (during development) to help me with it, and it it was pretty unweildly to work with when troubleshooting problems. YAML, I think, is the right way to store the data, but not in one, big file.
- Mark II: Multiple YAML Files - This is the current approach, where we have a directory of YAML files that are organized by type. For example, all of the family data is in
src/data/static/family.yaml, and all of the career data is insrc/data/static/career.yaml. This makes it much easier to work with, and also makes it easier for the LLM to help me with it. Then, there is a matching Jinja2 template for each YAML file that, when processed, generates a final Markdown file that is consumed by the RAG endpoint.
personal_info.yaml
") personal_info_yaml --Jinja2--> personal_info_md("
personal_info.md
") end
What is Jinja2?
Jinja2 is a templating engine for Python. It allows you to create templates that can be rendered with data. For example, you can create a template for a Markdown file, and then use Jinja2 to render that template with data from a YAML file. This allows you to have a single source of truth for the formatting, and then you can just update the YAML files as needed.
Then, we use a Jinja2 template to render the YAML files into Markdown files. The idea here is that we can have a single template file that has all of the formatting, and then we can use Jinja2 to render the YAML data into that template. This allows us to have a single source of truth for the formatting, and then we can just update the YAML files as needed.
Put another way, we use the YAML files to have sane, structured data (and there is a LOT that goes into building a dossier), and then we use Jinja2 to render the YAML data into Markdown files.
The ultimate result is a directory of Markdown files, properly-formatted that has all of the static and dynamic data. Then, the nomic process chunks all of that up into an FAISS vector database. More on how that is used, down below.
Summary
With this in mind, what does all of this give you? Well, the "RAG" part is where the magic happens. When you ask questions like:
- "Do I have any meetings today?"
- "What is the weather like today?"
- "What is my brother's name?"
The RAG API endpoint chunks up the Markdown files from above and creates a vector database of the contents. When you ask a question, it uses the vector database to find the most relevant information. Then, your question for the LLM is augmented with the data from the vector database so that the LLM can generate a response. So if you asked about your brother's name, Nomic/FAISS would see the sibling data that was rendered in the family.md file, and return some of that data back to the LLM. The LLM, now armed with that data, can then generate a response.
That's the basic idea behind an AI Personal Assistant, and one that is self-hosted in your home, and private. The project is on GitHub and has a very permissive MIT License. So, feel free to use it, modify it, and make it your own. I would love to see what you come up with! Also, if you want to contribute to this project, I welcome pull requests too!